Clustering – gruparea obiectelor similare în grupuri – este una dintre sarcinile fundamentale în domeniul analizei datelor și al Data Mining. Lista domeniilor de aplicație în care este utilizat este largă: segmentare de imagine, marketing, antifraudă, prognoză, analiză de text și multe altele. Pe scena modernă Clustering este adesea primul pas în analiza datelor. După identificarea grupurilor similare, se folosesc alte metode și se construiește un model separat pentru fiecare grup.
Problema grupării într-o formă sau alta a fost formulată în domenii științifice precum statistica, recunoașterea modelelor, optimizarea și învățarea automată. De aici și varietatea de sinonime pentru conceptul cluster - clasă, taxon, condensare.
În prezent, numărul de metode de împărțire a grupurilor de obiecte în clustere este destul de mare - câteva zeci de algoritmi și chiar mai multe modificări ale acestora. Cu toate acestea, suntem interesați de algoritmi de clustering din punctul de vedere al aplicării lor în Data Mining.
Clustering în Data Mining
Clustering în Data Mining devine valoroasă atunci când acționează ca una dintre etapele analizei datelor și construcției unei soluții analitice complete. Este adesea mai ușor pentru un analist să identifice grupuri de obiecte similare, să le studieze caracteristicile și să construiască pentru fiecare grup model separat decât să creăm un model general pe toate datele. Această tehnică este utilizată constant în marketing, identificând grupuri de clienți, cumpărători, produse și dezvoltând o strategie separată pentru fiecare dintre ei.
Foarte des, datele întâlnite de tehnologia Data Mining au următoarele caracteristici importante:
- dimensiune mare (mii de câmpuri) și volum mare (sute de mii și milioane de înregistrări) de tabele de baze de date și depozite de date (baze de date ultra-mari);
- seturile de date conțin numere mari numericȘi categoric atribute.
Toate atributele sau caracteristicile obiectelor sunt împărțite în numeric(numerice) și categoric(categoric). Atributele numerice sunt cele care pot fi ordonate în spațiu, în timp ce atributele categoriale sunt cele care nu pot fi ordonate. De exemplu, atributul „vârstă” este numeric, iar „culoarea” este categoric. Atribuirea valorilor atributelor are loc în timpul măsurătorilor cu tipul de scară selectat, iar aceasta, în general, este o sarcină separată.
Majoritatea algoritmilor de grupare implică compararea obiectelor între ele pe baza unei anumite măsuri de proximitate (similaritate). O măsură a proximității este o mărime care are o limită și crește odată cu creșterea proximității obiectelor. Măsurile de similaritate sunt „inventate” conform unor reguli speciale, iar alegerea măsurilor specifice depinde de sarcină, precum și de scara de măsurare. Este foarte des folosit ca măsură de proximitate pentru atributele numerice. distanta euclidiana, calculat prin formula:
$$D (x, y)=\sqrt(\sum_(i)((x-y)^2))$$
Necesitatea procesării unor cantități mari de date în Data Mining a condus la formularea unor cerințe pe care, dacă este posibil, algoritmul de clustering ar trebui să le satisfacă. Să ne uităm la ele:
- Număr minim posibil de treceri prin baza de date;
- Muncă limitată memorie cu acces aleator calculator;
- Algoritmul poate fi întrerupt și rezultatele intermediare salvate pentru a continua calculele mai târziu;
- Algoritmul ar trebui să funcționeze atunci când obiectele din baza de date pot fi preluate numai în modul cursor unidirecțional (adică, în modul de navigare înregistrare).
Va fi apelat un algoritm care satisface aceste cerințe (în special al doilea). scalabil(scalabil). Scalabilitatea este cea mai importantă proprietate a unui algoritm, în funcție de complexitatea sa de calcul și de implementarea software-ului. Există și o definiție mai încăpătoare. Un algoritm se numește scalabil dacă, cu o capacitate RAM constantă, timpul său de funcționare crește liniar odată cu creșterea numărului de înregistrări din baza de date.
Dar nu este întotdeauna necesar să procesați cantități extrem de mari de date. Prin urmare, în zorii formării teoriei analizei cluster, practic nu s-a acordat atenție scalabilității algoritmilor. S-a presupus că toate datele procesate se vor încadra în RAM; accentul principal a fost întotdeauna pe îmbunătățirea calității grupării. Este dificil să găsești un echilibru între clustering de înaltă calitate și scalabilitate. Prin urmare, în mod ideal, arsenalul Data Mining ar trebui să le includă pe ambele algoritmi eficienti clustering de microarrays și scalabil pentru procesarea bazelor de date mari.
Algoritmi de grupare: strălucire și mizerie
Deci, este deja posibilă clasificarea algoritmilor de cluster în scalabilȘi nescalabilă. Să continuăm clasificarea.
Pe baza metodei de împărțire în clustere, algoritmii sunt de două tipuri: ierarhici și neierarhici. Algoritmii ierarhici clasici funcționează numai cu atribute categoriale atunci când construiesc copac plin clustere imbricate. Metodele aglomerative pentru construirea ierarhiilor de cluster sunt comune aici - ele implică combinarea secvențială a obiectelor inițiale și o reducere corespunzătoare a numărului de clustere. Algoritmii ierarhici furnizează relativ calitate superioară clustering și nu necesită setarea preliminară a numărului de clustere. Cele mai multe dintre ele au complexitate O(n 2).
Algoritmii neierarhici se bazează pe optimizarea unei anumite funcții obiective care determină partiționarea optimă, într-un anumit sens, a unui set de obiecte în clustere. Populari în acest grup sunt algoritmii familiei k-means (k-means, fuzzy c-means, Gustafson-Kessel), care utilizează ca funcție obiectiv suma abaterilor ponderate la pătrat ale coordonatelor obiectului de la centrele clusterelor dorite. . Clusterele sunt căutate după forme sferice sau elipsoidale. În implementarea canonică, funcția este minimizată pe baza metodei multiplicatorului Lagrange și permite găsirea doar a minimului local cel mai apropiat. Utilizarea metodelor globale de căutare (algoritmi genetici) va crește semnificativ complexitatea de calcul a algoritmului.
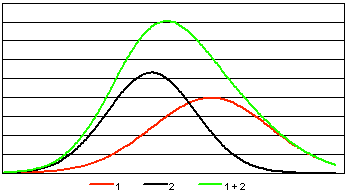
Dintre algoritmii non-ierarhici care nu se bazează pe distanță, trebuie evidențiat algoritmul EM (Expectation-Maximization). În ea, în loc de centre de cluster, se presupune că există o funcție de densitate de probabilitate pentru fiecare cluster cu valoarea și varianța corespunzătoare așteptărilor matematice. Într-un amestec de distribuții (Fig. 2), parametrii acestora (medii și abateri standard) sunt căutați utilizând principiul probabilității maxime. Algoritmul EM este una dintre implementările unei astfel de căutări. Problema este că, înainte de a începe algoritmul, se emite o ipoteză despre tipul de distribuții care sunt greu de estimat în setul de date global.
O altă problemă apare atunci când atributele unui obiect sunt amestecate - o parte este de tip numeric, iar cealaltă parte este de tip categorial. De exemplu, să presupunem că trebuie să calculați distanța dintre următoarele obiecte cu atribute (Vârsta, Sexul, Educația):
(1) (23, soț, mai mare)
(2) (25, femei, medie).
Primul atribut este numeric, restul sunt categoric. Dacă vrem să folosim un algoritm ierarhic clasic cu orice măsură de similaritate, va trebui să discredităm cumva atributul Vârstă. De exemplu, așa:
(1) (sub 30 de ani, soț, studii superioare)
(2) (până la 30 de ani, femeie, secundar).
În acest caz, cu siguranță vom pierde unele informații. Dacă definim distanța în spațiul euclidian, atunci vor apărea întrebări cu atribute categorice. Este clar că distanța dintre „Genul soțului” și „Genul soțiilor” este egală cu 0, deoarece valorile acestei caracteristici sunt în scala de numire. Iar atributul „Educație” poate fi măsurat atât în scara de nume, cât și în scara de ordine, atribuind anumite puncte fiecărei valori. Ce variantă ar trebui să aleg? Dar dacă atributele categoriale sunt mai importante decât cele numerice? Soluția la aceste probleme cade pe umerii analistului. În plus, atunci când se utilizează algoritmul k-means și altele similare, apar dificultăți în înțelegerea centrelor clusterelor de atribute categoriale și a priori setarea numărului de clustere.
Algoritmul de optimizare a funcției obiectiv în algoritmi non-ierarhici bazați pe distanță este de natură iterativă, iar la fiecare iterație este necesar să se calculeze o matrice a distanțelor dintre obiecte. La un numar mare obiecte, acest lucru este ineficient și necesită resurse de calcul serioase. Complexitatea de calcul a primei iterații a algoritmului k-medii este estimată ca O(kmn), unde k,m,n este numărul de clustere, atribute și respectiv obiecte. Dar pot exista o mulțime de iterații! Va trebui să faceți multe treceri prin setul de date.
Abordarea în sine cu ideea de a căuta grupuri de formă sferică sau elipsoidală are o mulțime de dezavantaje în k-means. Abordarea funcționează bine atunci când datele din spațiu formează aglomerări compacte care se pot distinge clar unele de altele. Și dacă datele sunt imbricate, atunci niciunul dintre algoritmii k-means nu va face față vreodată unei astfel de sarcini. De asemenea, algoritmul nu funcționează bine în cazul în care un cluster este mult mai mare decât celelalte și sunt aproape unul de celălalt - are loc efectul „divizării” unui cluster mare (Fig. 3).

Cu toate acestea, cercetările în domeniul îmbunătățirii algoritmilor de clustering sunt în curs de desfășurare. Au fost dezvoltate extensii interesante ale algoritmului k-means pentru a lucra cu atribute categoriale (k-moduri) și atribute mixte (k-prototipuri). De exemplu, k-prototypes calculează distanțele dintre obiecte diferit, în funcție de tipul de atribut.
Pe piața algoritmilor de clustering scalabili, lupta este de a reduce fiecare trecere „în plus” prin setul de date în timp ce algoritmul rulează. S-au dezvoltat analogi scalabili ai k-means și EM (scalable k-means and scalable EM), metode aglomerative scalabile (CURE, CACTUS). Acești algoritmi de ultimă generație necesită doar câteva (două până la zece) scanări ale bazei de date înainte de a obține gruparea finală.
Obținerea algoritmilor scalabili se bazează pe ideea de a abandona local functii de optimizare. Compararea în perechi a obiectelor între ele în algoritmul k-means nu este altceva decât optimizare locală, deoarece La fiecare iterație, este necesar să se calculeze distanța de la centrul clusterului la fiecare obiect. Acest lucru duce la costuri de calcul ridicate. La setare global funcții de optimizare, adăugarea unui punct nou la cluster nu necesită calcule mari: se calculează pe baza valorii vechi, a noului obiect și a așa-numitului caracteristicile clusterului(caracteristicile clusterelor). Caracteristicile specifice ale clusterului depind de un anumit algoritm. Așa au apărut algoritmii BIRCH, LargeItem, CLOPE și mulți alții.
Astfel, nu există un singur algoritm de clustering universal. Când utilizați orice algoritm, este important să înțelegeți avantajele și dezavantajele acestuia, luați în considerare natura datelor cu care funcționează cel mai bine și capacitatea sa de a se scala.
Literatură
- Bradley, P., Fayyad, U., Reina, C. Scaling Clustering Algorithms to Large Databases, Proc. 4th Int"l Conf. Knowledge Discovery and Data Mining, AAAI Press, Menlo Park, California, 1998.
- Zhang, T., Ramakrishnan, R., Livny, M. Birch: O metodă eficientă de grupare a datelor pentru baze de date mari, Proc. ACM SIGMOD Int'l Conf. Management of Data, ACM Press, New York, 1996.
- Paul S. Bradley, Usama M. Fayyad, Cory A. Reina Scaling EM (Expectation-Maximization) Clustering to Large Databases, Microsoft Research, 1999.
- Z. Huang. Clustering seturi mari de date cu valori numerice și categoriale mixte. În Prima Conferință Pacific-Asia privind descoperirea cunoștințelor și extragerea datelor, 1997.
- Milenova, B., Campos, M. Clustering baze de date mari cu valori numerice și nominale folosind proiecții ortogonale, Oracle Data Mining Technologies, 2002.
- Z. Huang. Un algoritm de clustering rapid pentru a grupa seturi de date categorice foarte mari în Data Mining. Probleme de cercetare privind data mining și KDD, 1997.
- Wang, K., Xu, C.. Liu, B. Clustering tranzacții folosind articole mari. În Proc. CIKM'99, Kansas, Missouri, 1999.
- Guha S., Rastogi R., Shim K. CURE: An Efficient Clustering Algorithm for Large Databases, Proc. ACM SIGMOD Int'l Conf. Management of Data, ACM Press, New York, 1998.
- Ganti V., Gerhke J., Ramakrishan R. CACTUS – Clustering Categorical Data Using Summaries. În Proc KDD'99, 1999.
- J. Bilmes. Un tutorial blând despre algoritmul EM și aplicarea acestuia la estimarea parametrilor pentru amestecuri gaussiene și modele Markov ascunse, Tech. Raport ICSI-TR-97-021, 1997.
- Exploatarea datelor în baze de date ultra-mari / V. Ganti, J. Gerke, R. Ramakrishnan // Sisteme deschise, №9-10, 1999.
- Barseghyan et al.Metode și modele de analiză a datelor: OLAP și Data Mining. – Sankt Petersburg, 2004.
Știm că Pământul este una dintre cele 8 planete care se învârt în jurul Soarelui. Soarele este doar o stea dintre cele aproximativ 200 de miliarde de stele din galaxia Calea Lactee. Este foarte greu de înțeles acest număr. Știind acest lucru, putem face o presupunere despre numărul de stele din univers - aproximativ 4X10^22. Putem vedea aproximativ un milion de stele pe cer, deși aceasta este doar o mică parte din numărul real de stele. Deci, avem două întrebări:
- Ce este o galaxie?
- Și care este legătura dintre galaxii și subiectul articolului (analiza cluster)
O galaxie este o colecție de stele, gaze, praf, planete și nori interstelari. De obicei, galaxiile seamănă cu o spirală sau o figură edeptică. În spațiu, galaxiile sunt separate unele de altele. Găurile negre uriașe sunt adesea centrele majorității galaxiilor.
După cum vom discuta în secțiunea următoare, există multe asemănări între galaxii și analiza clusterelor. Galaxiile există în spațiul tridimensional, analiza cluster este analiza multivariată, realizat în spațiu n-dimensional.
Nota: O gaură neagră este centrul unei galaxii. Vom folosi o idee similară cu privire la centroizi pentru analiza clusterului.
Analiza grupului
Să presupunem că ești șeful departamentului de marketing și relații cu consumatorii la o companie de telecomunicații. Înțelegi că fiecare consumator este diferit și că ai nevoie de strategii diferite pentru a atrage diferiți consumatori. Veți aprecia puterea unui astfel de instrument precum segmentarea clienților pentru a optimiza costurile. Pentru a vă reîmprospăta cunoștințele despre analiza cluster, luați în considerare următorul exemplu care ilustrează 8 consumatori și durata medie a apelurilor lor (locale și internaționale). Datele de mai jos:
Pentru o mai bună înțelegere, să desenăm un grafic în care axa x va afișa durata medie a apelurilor internaționale, iar axa y va afișa durata medie a apelurilor locale. Mai jos este graficul:

Nota: Acest lucru este similar cu analiza aranjamentului stelelor pe cerul nopții (aici stelele sunt înlocuite de consumatori). În plus, în loc de un spațiu tridimensional, avem unul bidimensional, definit de durata apelurilor locale și internaționale ca axele x și y.
Acum, vorbind în termeni de galaxii, sarcina este formulată după cum urmează - să găsim poziția găurilor negre; în analiza clusterelor acestea se numesc centroizi. Pentru a detecta centroizii, vom începe prin a lua puncte arbitrare ca poziții de centru.
Distanța euclidiană pentru a găsi centroizii pentru clustere
În cazul nostru, vom plasa în mod arbitrar doi centroizi (C1 și C2) în puncte cu coordonatele (1, 1) și (3, 4). De ce am ales acești doi centroizi? Afișarea vizuală a punctelor de pe grafic ne arată că există două clustere pe care le vom analiza. Cu toate acestea, vom vedea mai târziu că răspunsul la această întrebare nu este atât de simplu pentru un set mare de date.În continuare, vom măsura distanța dintre centroizi (C1 și C2) și toate punctele de pe grafic folosind formula euclidiană pentru a găsi distanța dintre două puncte.
Notă: Distanța poate fi calculată folosind alte formule, de exemplu,
- distanță euclidiană pătrată – pentru a da greutate obiectelor care sunt mai îndepărtate unele de altele
- Distanța Manhattan – pentru a reduce impactul emisiilor
- Distanța de putere – pentru a crește/scădea influența de-a lungul unor coordonate specifice
- procent de dezacord – pentru date categorice
- si etc.
Apartenența centroidului (ultima coloană) este calculată pe baza apropierii de centroizi (C1 și C2). Primul consumator este mai aproape de centroidul #1 (1,41 comparativ cu 2,24) și, prin urmare, aparține clusterului cu centroidul C1.

Mai jos este un grafic care ilustrează centroizii C1 și C2 (prezentați ca un diamant albastru și portocaliu). Consumatorii sunt reprezentați de culoarea centroidului corespunzător căruia i-au fost alocați.

Deoarece am selectat aleatoriu centroizii, al doilea pas este să facem această selecție iterativă. Pozitie noua centroizii este ales ca medie pentru punctele clusterului corespunzător. Deci, de exemplu, pentru primul centroid (aceștia sunt consumatorii 1, 2 și 3). Prin urmare, noua coordonată x pentru centroidul C1 este coordonata x medie a acestor consumatori (2+1+1)/3 = 1,33. Vom obține noi coordonate pentru C1 (1.33, 2.33) și C2 (4.4, 4.2). Noul grafic este mai jos:

În cele din urmă, vom plasa centroizii în centrul clusterului corespunzător. Graficul de mai jos:

Pozițiile găurilor noastre negre (centrele clusterelor) din exemplul nostru sunt C1 (1,75, 2,25) și C2 (4,75, 4,75). Cele două grupuri de deasupra sunt ca două galaxii separate în spațiu una de cealaltă.
Deci, să ne uităm la exemple în continuare. Să ne confruntăm cu sarcina de a segmenta consumatorii în funcție de doi parametri: vârsta și venitul. Să presupunem că avem 2 consumatori, cu vârsta de 37 și 44 de ani, cu venituri de 90.000 USD, respectiv 62.000 USD. Dacă vrem să măsurăm distanța euclidiană dintre punctele (37, 90000) și (44, 62000), vedem că în în acest caz, variabila venit „domină” variabila vârstă și modificarea acesteia are un efect puternic asupra distanței. Avem nevoie de o strategie pentru a rezolva această problemă, altfel analiza noastră va da un rezultat incorect. Soluția la această problemă este să ne aducem valorile la scări comparabile. Normalizarea este soluția la problema noastră.
Normalizarea datelor
Există multe abordări pentru normalizarea datelor. De exemplu, normalizarea minim-maxim. Pentru această normalizare se utilizează următoarea formulăîn acest caz X* este valoarea normalizată, min și max sunt coordonatele minime și maxime pentru întregul set X
(Rețineți că această formulă plasează toate coordonatele pe segment)
Luați în considerare exemplul nostru, haideți venitul maxim 130.000 USD, iar minimul este de 45.000 USD. Valoarea normalizată a venitului pentru consumatorul A este
![]()
Vom face acest exercițiu pentru toate punctele pentru fiecare variabilă (coordonate). Venitul pentru al doilea consumator (62000) va deveni 0,2 după procedura de normalizare. În plus, vârstele minime și maxime trebuie să fie 23, respectiv 58 de ani. După normalizare, vârstele celor doi consumatori ai noștri vor fi 0,4 și 0,6.
Este ușor de observat că toate datele noastre se încadrează acum între valorile 0 și 1. Prin urmare, acum avem seturi de date normalizate pe scale comparabile.
Rețineți, înainte de procedura de analiză a clusterului, trebuie efectuată normalizarea.
Tipuri de intrare
- Descrierea caracteristicilor obiectelor. Fiecare obiect este descris de un set al caracteristicilor sale, numit semne. Caracteristicile pot fi numerice sau nenumerice.
- Matricea distanțelor dintre obiecte. Fiecare obiect este descris prin distanțe față de toate celelalte obiecte din setul de antrenament.
Obiectivele grupării
- Înțelegerea datelor prin identificarea structurii clusterului. Împărțirea eșantionului în grupuri de obiecte similare vă permite să simplificați procesare ulterioara date și luarea deciziilor, aplicând o metodă diferită de analiză fiecărui cluster (strategie „divide and cuquer”).
- Comprimarea datelor. Dacă eșantionul original este excesiv de mare, atunci îl puteți reduce, lăsând unul dintre cele mai tipice reprezentative din fiecare grup.
- Detectarea noutății detectarea noutății). Sunt identificate obiecte atipice care nu pot fi atașate la niciunul dintre clustere.
În primul caz, ei încearcă să micșoreze numărul de clustere. În al doilea caz, este mai important să se asigure un grad ridicat de similitudine a obiectelor din cadrul fiecărui cluster și poate exista orice număr de clustere. În al treilea caz, cele mai interesante sunt obiectele individuale care nu se încadrează în niciunul dintre clustere.
În toate aceste cazuri, se poate folosi gruparea ierarhică, atunci când clusterele mari sunt împărțite în altele mai mici, care la rândul lor sunt împărțite în altele și mai mici etc. Astfel de probleme se numesc probleme de taxonomie.
Taxonomia are ca rezultat o structură ierarhică arborescentă. În acest caz, fiecare obiect se caracterizează prin enumerarea tuturor clusterelor cărora le aparține, de obicei de la mare la mic.
Exemplul clasic de taxonomie bazată pe asemănări este nomenclatura binomială a viețuitoarelor propusă de Carl Linnaeus la mijlocul secolului al XVIII-lea. Sistematizări similare sunt construite în multe domenii ale cunoașterii pentru a organiza informații despre un număr mare de obiecte.
Metode de grupare
Formularea formală a problemei de clustering
Fie un set de obiecte și fie un set de numere (nume, etichete) de clustere. Este specificată funcția de distanță între obiecte. Există un eșantion finit de antrenament de obiecte. Este necesară împărțirea eșantionului în subseturi disjunse numite clustere, astfel încât fiecare cluster este format din obiecte care sunt similare ca metrică, iar obiectele diferitelor clustere sunt semnificativ diferite. În acest caz, fiecărui obiect i se atribuie un număr de grup.
Algoritmul de grupare este o funcție care atribuie un număr de grup oricărui obiect. În unele cazuri, setul este cunoscut dinainte, dar cel mai adesea sarcina este de a determina numărul optim de clustere, din punctul de vedere al unuia sau altuia. criterii de calitate gruparea.
Literatură
- Ayvazyan S. A., Buchstaber V. M., Enyukov I. S., Meshalkin L. D. Statistică aplicată: clasificare și reducerea dimensionalității. - M.: Finanțe și Statistică, 1989.
- Zhuravlev Yu. I., Ryazanov V. V., Senko O. V."Recunoaştere". Metode matematice. Sistem software. Aplicații practice. - M.: Phazis, 2006. ISBN 5-7036-0108-8.
- Zagoruiko N. G. Metode aplicate de analiză a datelor și a cunoștințelor. - Novosibirsk: IM SB RAS, 1999. ISBN 5-86134-060-9.
- Mandel I.D. Analiza grupului. - M.: Finanţe şi Statistică, 1988. ISBN 5-279-00050-7.
- Shlesinger M., Hlavach V. Zece prelegeri despre recunoașterea statistică și a structurii. - Kiev: Naukova Dumka, 2004. ISBN 966-00-0341-2.
- Hastie T., Tibshirani R., Friedman J. Elementele învăţării statistice. - Springer, 2001. ISBN 0-387-95284-5.
- Jain, Murty, Flynn Gruparea datelor: o revizuire. // ACM Comput. Surv. 31 (3) , 1999
linkuri externe
In rusa
- www.MachineLearning.ru - resursă wiki profesională dedicată învățării automate și extragerii datelor
- S. Nikolenko. Slide slide-uri despre algoritmii de grupare
În limba engleză
- COMPACT - Pachet comparativ pentru evaluarea grupării. Un pachet Matlab gratuit, 2006.
- P. Berkhin, Sondajul tehnicilor de extragere a datelor în cluster, Accrue Software, 2002.
- Jain, Murty și Flynn: Clustering de date: o revizuire,ACM Comp. Surv., 1999.
- pentru o altă prezentare a ierarhice, k-means și fuzzy c-means, vedeți această introducere în clustering. Are, de asemenea, o explicație despre amestecul de gaussieni.
- David Dowe, Pagina de modelare a amestecurilor- alte legături de modele de clustering și amestec.
- un tutorial despre clustering
- Manualul on-line: Teoria informației, inferența și algoritmii de învățare, de David J.C. MacKay include capitole despre clustering k-means, soft k-means clustering și derivații, inclusiv algoritmul E-M și vizualizarea variațională a algoritmului E-M.
- „The Self-Organized Gene”, tutorial care explică gruparea prin învățare competitivă și hărți de auto-organizare.
- kernlab - pachet R pentru învățarea automată bazată pe kernel (include implementarea grupării spectrale)
- Tutorial - Tutorial cu introducerea algoritmilor de clusterizare (k-means, fuzzy-c-means, ierarhic, amestec de gaussiani) + câteva demonstrații interactive (applet-uri java)
- Software de extragere a datelor - Software-ul de extragere a datelor utilizează frecvent tehnici de grupare.
- Aplicație Java Competitive Learning O suită de rețele neuronale nesupravegheate pentru clustering. Scris în Java. Complet cu tot codul sursă.
Tipuri de intrare
- Descrierea caracteristicilor obiectelor. Fiecare obiect este descris de un set al caracteristicilor sale, numit semne. Caracteristicile pot fi numerice sau nenumerice.
- Matricea distanțelor dintre obiecte. Fiecare obiect este descris prin distanțe față de toate celelalte obiecte din setul de antrenament.
Matricea distanței poate fi calculat dintr-o matrice de descrieri de caracteristici ale obiectelor într-un număr infinit de moduri, în funcție de modul în care se introduce funcția de distanță (metrică) între descrierile de caracteristici. Metrica euclidiană este adesea folosită, dar această alegere în cele mai multe cazuri este o euristică și se datorează doar unor motive de comoditate.
Problema inversă - restabilirea descrierilor caracteristicilor dintr-o matrice de distanțe în perechi dintre obiecte - în cazul general nu are soluție, iar soluția aproximativă nu este unică și poate avea o eroare semnificativă. Această problemă este rezolvată prin metode de scalare multidimensională.
Astfel, formularea problemei de clustering conform matricea distanțelor este mai general. Pe de altă parte, dacă sunt disponibile descrieri de caracteristici, este adesea posibil să se construiască metode de grupare mai eficiente.
Obiectivele grupării
- Înțelegerea datelor prin identificarea structurii clusterului. Împărțirea eșantionului în grupuri de obiecte similare face posibilă simplificarea ulterioară a procesării datelor și a luării deciziilor prin aplicarea unei metode de analiză diferite pentru fiecare grup (strategia „împărți și cuceri”).
- Comprimarea datelor. Dacă eșantionul original este excesiv de mare, atunci îl puteți reduce, lăsând unul dintre cele mai tipice reprezentative din fiecare grup.
- Detectare noutate. Sunt identificate obiecte atipice care nu pot fi atașate la niciunul dintre clustere.
În primul caz, ei încearcă să micșoreze numărul de clustere. În al doilea caz, este mai important să se asigure un grad ridicat (sau fix) de similitudine a obiectelor din cadrul fiecărui cluster și poate exista orice număr de clustere. În al treilea caz, cele mai interesante sunt obiectele individuale care nu se încadrează în niciunul dintre clustere.
În toate aceste cazuri, se poate folosi gruparea ierarhică, atunci când clusterele mari sunt împărțite în altele mai mici, care la rândul lor sunt împărțite în altele și mai mici etc. Astfel de probleme se numesc probleme de taxonomie.
Taxonomia are ca rezultat o structură ierarhică arborescentă. În acest caz, fiecare obiect se caracterizează prin enumerarea tuturor clusterelor cărora le aparține, de obicei de la mare la mic. Din punct de vedere vizual, taxonomia este reprezentată sub forma unui grafic numit dendrogramă.
Un exemplu clasic de taxonomie bazată pe asemănări este nomenclatura binomială a viețuitoarelor, propus de Carl Linnaeus la mijlocul secolului al XVIII-lea. Sistematizări similare sunt construite în multe domenii ale cunoașterii pentru a organiza informații despre un număr mare de obiecte.
Funcții de distanță
Metode de grupare
- Algoritmi de grupare statistică
- Grupare ierarhică sau taxonomie
Formularea formală a problemei de clustering
Fie un set de obiecte și fie un set de numere (nume, etichete) de clustere. Este specificată funcția de distanță între obiecte. Există un eșantion finit de antrenament de obiecte. Este necesară împărțirea eșantionului în subseturi disjunse numite clustere, astfel încât fiecare cluster este format din obiecte care sunt similare ca metrică, iar obiectele diferitelor clustere sunt semnificativ diferite. În acest caz, fiecărui obiect i se atribuie un număr de grup.
Algoritmul de grupare este o funcție care atribuie un număr de grup oricărui obiect. În unele cazuri, setul este cunoscut dinainte, dar cel mai adesea sarcina este de a determina numărul optim de clustere, din punctul de vedere al unuia sau altuia. criterii de calitate gruparea.
Clustering (învățare nesupravegheată) diferă de clasificare (învățare supravegheată) prin aceea că etichetele obiectelor originale nu sunt specificate inițial, iar setul în sine poate fi chiar necunoscut.
Soluția la problema de clustering este fundamental ambiguă și există mai multe motive pentru aceasta:
- Nu există clar cel mai bun criteriu calitatea grupării. Sunt cunoscute o serie de criterii euristice, precum și o serie de algoritmi care nu au un criteriu clar definit, dar realizează o grupare destul de rezonabilă „prin construcție”. Toate pot da rezultate diferite.
- Numărul de clustere nu este de obicei cunoscut în prealabil și este stabilit în funcție de un criteriu subiectiv.
- Rezultatul grupării depinde în mod semnificativ de metrica, a cărei alegere, de regulă, este, de asemenea, subiectivă și determinată de un expert.
Legături
- Vorontsov K.V. Metode matematice de predare din cazuri. MIPT (2004), Matematică computațională și cultură a Universității de Stat din Moscova (2007).
- Serghei Nikolenko. Slide-urile cursului „Algoritmi de grupare 1” și „Algoritmi de grupare 2”. Curs „Sisteme de autoînvățare”.
Literatură
- Ayvazyan S. A., Buchstaber V. M., Enyukov I. S., Meshalkin L. D. Statistică aplicată: clasificare și reducerea dimensionalității. - M.: Finanțe și Statistică, 1989.
- Zhuravlev Yu. I., Ryazanov V. V., Senko O. V."Recunoaştere". Metode matematice. Sistem software. Aplicații practice. - M.: Faza, 2006. .
- Zagoruiko N. G. Metode aplicate de analiză a datelor și a cunoștințelor. - Novosibirsk: IM SB RAS, 1999. .
- Mandel I.D. Analiza grupului. - M.: Finanţe şi Statistică, 1988. .
- Shlesinger M., Hlavach V. Zece prelegeri despre recunoașterea statistică și a structurii. - Kiev: Naukova Dumka, 2004. .
- Hastie T., Tibshirani R., Friedman J. Elementele învăţării statistice. - Springer, 2001. .
Salutari!
În a lui munca de diploma Am făcut un review și analiza comparativa algoritmi de grupare a datelor. M-am gândit că materialul deja adunat și prelucrat ar putea fi interesant și util cuiva.
Am vorbit despre ce este gruparea în articol. Voi repeta parțial cuvintele lui Alexandru și le voi adăuga parțial. Tot la finalul acestui articol, cei interesați pot citi materialele prin linkurile din bibliografie.
De asemenea, am încercat să aduc stilul sec de prezentare „absolvent” la unul mai jurnalistic.
Conceptul de clustering
Clustering (sau analiza cluster) este sarcina de a împărți un set de obiecte în grupuri numite clustere. În cadrul fiecărui grup ar trebui să existe obiecte „similare” și obiecte grupuri diferite ar trebui să fie cât mai diferite. Principala diferență dintre grupare și clasificare este că lista de grupuri nu este clar definită și este determinată în timpul funcționării algoritmului.Aplicarea analizei cluster în vedere generala se reduce la următorii pași:
- Selectarea unui eșantion de obiecte pentru grupare.
- Definirea unui set de variabile prin care obiectele din eșantion vor fi evaluate. Dacă este necesar, normalizați valorile variabilelor.
- Calculul valorilor de măsurare a similitudinii dintre obiecte.
- Aplicarea metodei de analiză a clusterelor pentru a crea grupuri de obiecte similare (clustere).
- Prezentarea rezultatelor analizei.
Măsuri de distanță
Deci, cum determinăm „asemănarea” obiectelor? În primul rând, trebuie să creați un vector de caracteristici pentru fiecare obiect - de regulă, acesta este un set de valori numerice, de exemplu, înălțimea și greutatea unei persoane. Cu toate acestea, există și algoritmi care funcționează cu caracteristici calitative (așa-numitele categorice).Odată ce am determinat vectorul caracteristică, normalizarea poate fi efectuată astfel încât toate componentele să contribuie în mod egal la calculul „distanței”. În timpul procesului de normalizare, toate valorile sunt aduse într-un anumit interval, de exemplu, [-1, -1] sau .
În cele din urmă, pentru fiecare pereche de obiecte, se măsoară „distanța” dintre ele - gradul de similitudine. Există multe valori, iată doar cele principale:
Alegerea metricii revine în întregime cercetătorului, deoarece rezultatele grupării pot diferi semnificativ atunci când se utilizează măsuri diferite.
Clasificarea algoritmilor
Pentru mine, am identificat două clasificări principale ale algoritmilor de grupare.- Ierarhic și plat.
Algoritmii ierarhici (numiți și algoritmi de taxonomie) construiesc nu doar o partiție a eșantionului în clustere disjunse, ci un sistem de partiții imbricate. Acea. Ca rezultat, obținem un copac de ciorchini, a cărui rădăcină este întregul eșantion, iar frunzele sunt cele mai mici clustere.
Algoritmii plat construiesc o partiție de obiecte în clustere. - Clar și neclar.
Algoritmi clari (sau care nu se suprapun) atribuie fiecărui obiect eșantion un număr de grup, de ex. fiecare obiect aparține unui singur cluster. Algoritmii fuzzy (sau care se intersectează) atribuie fiecărui obiect un set de valori reale care arată gradul de relație a obiectului cu clusterele. Acestea. fiecare obiect aparține fiecărui grup cu o anumită probabilitate.
Fuzionarea clusterelor
În cazul utilizării algoritmilor ierarhici, se pune întrebarea cum să combinați grupurile între ele, cum să calculați „distanțele” dintre ele. Există mai multe valori:- Legătură unică (cea mai apropiată distanță de vecin)
În această metodă, distanța dintre două grupuri este determinată de distanța dintre cele mai apropiate două obiecte (cei mai apropiati vecini) în grupuri diferite. Grupurile rezultate tind să formeze lanțuri. - Conectivitate completă (distanța celor mai îndepărtați vecini)
În această metodă, distanțele dintre grupuri sunt determinate de cea mai mare distanță dintre oricare două obiecte din grupuri diferite (adică, cei mai îndepărtați vecini). Această metodă funcționează de obicei foarte bine atunci când obiectele provin din grupuri separate. Dacă ciorchinii au o formă alungită sau lor tip natural este „înlănțuit”, atunci această metodă este nepotrivită. - Medie neponderată pe perechi
În această metodă, distanța dintre două grupuri diferite este calculată ca distanța medie dintre toate perechile de obiecte din ele. Metoda este eficientă atunci când obiectele formează grupuri diferite, dar funcționează la fel de bine în cazul clusterelor extinse (de tip „lanț”). - Media ponderată pe perechi
Metoda este identică cu metoda medie neponderată pe perechi, cu excepția faptului că dimensiunea clusterelor corespunzătoare (adică numărul de obiecte pe care le conțin) este utilizată ca factor de ponderare în calcule. Prin urmare, această metodă ar trebui utilizată atunci când sunt de așteptat dimensiuni inegale ale clusterelor. - Metoda centroidului neponderat
În această metodă, distanța dintre două grupuri este definită ca distanța dintre centrele lor de greutate. - Metoda centroidului ponderat (mediană)
Această metodă este identică cu cea anterioară, cu excepția faptului că calculul utilizează ponderi pentru a ține seama de diferențele dintre dimensiunile clusterului. Prin urmare, dacă există sau sunt suspectate diferențe semnificative în dimensiunea clusterelor, această metodă este de preferat celei anterioare.
Prezentare generală a algoritmilor
Algoritmi de grupare ierarhică
Printre algoritmii de grupare ierarhică, există două tipuri principale: algoritmi de jos în sus și de sus în jos. Algoritmii de sus în jos funcționează pe un principiu de sus în jos: la început, toate obiectele sunt plasate într-un singur grup, care este apoi împărțit în grupuri din ce în ce mai mici. Mai obișnuiți sunt algoritmii de jos în sus, care încep prin plasarea fiecărui obiect într-un grup separat și apoi combinând grupurile în altele din ce în ce mai mari până când toate obiectele din eșantion sunt conținute într-un singur grup. În acest fel, se construiește un sistem de partiții imbricate. Rezultatele unor astfel de algoritmi sunt de obicei prezentate sub forma unui arbore - o dendrogramă. Un exemplu clasic de astfel de copac este clasificarea animalelor și plantelor.Pentru a calcula distanțele dintre clustere, toată lumea folosește cel mai adesea două distanțe: o singură legătură sau o legătură completă (consultați prezentarea generală a măsurilor distanței dintre clustere).
Un dezavantaj al algoritmilor ierarhici este sistemul de partiții complete, care poate fi inutil în contextul problemei care se rezolvă.
Algoritmi de eroare cuadratică
Problema grupării poate fi considerată ca construirea unei partiții optime a obiectelor în grupuri. În acest caz, optimitatea poate fi definită ca cerința de a minimiza eroarea pătratică medie a partiționării:
Unde c j- „centrul de masă” al clusterului j(punct cu caracteristici medii pentru un cluster dat).
Algoritmii de eroare cuadratică sunt un tip de algoritmi plati. Cel mai comun algoritm din această categorie este metoda k-means. Acest algoritm construiește număr dat clustere situate cât mai departe unul de celălalt. Lucrarea algoritmului este împărțită în mai multe etape:
- Selectați aleatoriu k puncte care sunt „centrele de masă” inițiale ale clusterelor.
- Atribuiți fiecare obiect grupului cu cel mai apropiat „centru de masă”.
- Recalculați „centrele de masă” ale clusterelor în funcție de compoziția lor actuală.
- Dacă criteriul de oprire a algoritmului nu este satisfăcut, reveniți la pasul 2.
Dezavantajele acestui algoritm includ necesitatea de a specifica numărul de clustere pentru partiționare.
Algoritmi fuzzy
Cel mai popular algoritm de grupare fuzzy este algoritmul c-means. Este o modificare a metodei k-means. Etapele algoritmului:
Acest algoritm poate să nu fie potrivit dacă numărul de clustere este necunoscut în prealabil sau dacă este necesar să se atribuie fără ambiguitate fiecare obiect unui cluster.
Algoritmi bazați pe teoria grafurilor
Esența unor astfel de algoritmi este că o selecție de obiecte este reprezentată sub forma unui grafic G=(V, E), ale căror vârfuri corespund obiectelor și ale căror margini au o pondere egală cu „distanța” dintre obiecte. Avantajele algoritmilor de grupare grafică sunt claritatea, ușurința relativă de implementare și capacitatea de a introduce diverse îmbunătățiri bazate pe considerații geometrice. Algoritmii principali sunt algoritmul pentru identificarea componentelor conectate, algoritmul pentru construirea unui arbore de acoperire minim și algoritmul de clustering strat cu strat.Algoritm pentru identificarea componentelor conectate
În algoritmul de identificare a componentelor conectate este specificat parametrul de intrare R iar în grafic sunt șterse toate muchiile pentru care „distanțele” sunt mai mari R. Doar cele mai apropiate perechi de obiecte rămân conectate. Scopul algoritmului este de a selecta o astfel de valoare R, situat în intervalul tuturor „distanțelor” la care graficul „se destramă” în mai multe componente conectate. Componentele rezultate sunt clustere.Pentru a selecta un parametru R De obicei, se construiește o histogramă de distribuții ale distanțelor pe perechi. În sarcinile cu o structură de cluster de date bine definită, histograma va avea două vârfuri - unul corespunde distanțelor intra-cluster, al doilea - distanțe inter-cluster. Parametru R este selectat din zona minimă dintre aceste vârfuri. În același timp, este destul de dificil să controlezi numărul de clustere folosind un prag de distanță.
Algoritmul arborelui de acoperire minim
Algoritmul arborelui de întindere minimă construiește mai întâi un arbore de întindere minim pe un grafic și apoi elimină secvențial muchiile cu cea mai mare greutate. Figura arată arborele de acoperire minim obținut pentru nouă obiecte.
Prin eliminarea unui link etichetat CD cu o lungime de 6 unități (margine cu distanta maxima), obținem două grupuri: (A, B, C) și (D, E, F, G, H, I). Al doilea cluster poate fi împărțit ulterior în alte două clustere prin eliminarea marginii EF, care are o lungime de 4,5 unități.
Grupare strat cu strat
Algoritmul de grupare strat cu strat se bazează pe identificarea componentelor grafice conectate la un anumit nivel de distanțe între obiecte (vârfurile). Nivelul distanței este stabilit de pragul distanței c. De exemplu, dacă distanța dintre obiecteAlgoritmul de grupare strat cu strat generează o secvență de subgrafe ale graficului G, care reflectă relațiile ierarhice dintre clustere:
![]() ,
,
Unde G t = (V, E t)- graficul nivelului cu T,![]() ,
,
cu T– al-lea prag de distanță,
m – numărul de niveluri ierarhice,
G 0 = (V, o), o este setul gol de muchii ale graficului obținut de t 0 = 1,
G m = G, adică un grafic al obiectelor fără restricții de distanță (lungimea marginilor graficului), deoarece t m = 1.
Prin modificarea pragurilor de distanță ( s 0 , …, s m), unde 0 = de la 0 < de la 1 < …< cu m= 1, este posibil să se controleze adâncimea ierarhiei clusterelor rezultate. Astfel, algoritmul de grupare strat cu strat este capabil să creeze atât o partiție plată, cât și ierarhică a datelor.
Compararea algoritmilor
Complexitatea computațională a algoritmilorTabel de comparare a algoritmului
| Algoritmul de grupare | Forma grupului | Date de intrare | rezultate |
| Ierarhic | gratuit | Numărul de clustere sau pragul de distanță pentru trunchierea ierarhiei | Arborele cluster binar |
| k-înseamnă | Hipersferă | Numărul de clustere | Centrele de clustere |
| c-înseamnă | Hipersferă | Numărul de clustere, gradul de neclaritate | Centre de cluster, matrice de membri |
| Selectarea componentelor conectate | gratuit | Pragul distantei R | |
| Arborele de întindere minim | gratuit | Numărul de grupuri sau pragul de distanță pentru eliminarea marginilor | Structura arborescentă a clusterelor |
| Grupare strat cu strat | gratuit | Secvența pragurilor de distanță | Structura arborescentă a clusterelor cu la diferite niveluri ierarhie |
Un pic despre aplicare
În munca mea, trebuia să selectez zone individuale din structurile ierarhice (arbori). Acestea. în esență, a fost necesar să tăiem copacul original în mai mulți copaci mici. Deoarece un arbore direcționat este un caz special al unui graf, algoritmii bazați pe teoria grafurilor sunt o potrivire naturală.Spre deosebire de un graf complet conectat, într-un arbore direcționat nu toate vârfurile sunt conectate prin muchii, iar numărul total de muchii este n–1, unde n este numărul de vârfuri. Acestea. în ceea ce privește nodurile de arbore, munca algoritmului de identificare a componentelor conectate va fi simplificată, deoarece eliminarea oricărui număr de muchii va „rupe” arborele în componente conectate (arbori individuali). Algoritmul arborelui de acoperire minim în acest caz va coincide cu algoritmul de selectare a componentelor conectate - prin eliminarea celor mai lungi margini, arborele original este împărțit în mai mulți arbori. În acest caz, este evident că faza de construire a arborelui de întindere minim în sine este omisă.
Dacă s-ar folosi alți algoritmi, aceștia ar trebui să ia în considerare separat prezența conexiunilor între obiecte, ceea ce complică algoritmul.
Separat, aș dori să spun că pentru a realiza cel mai bun rezultat este necesar să experimentați alegerea măsurilor de distanță și, uneori, chiar să schimbați algoritmul. Nu există o soluție unică.



