Kümeleme (benzer nesnelerin gruplar halinde gruplanması) veri analizi ve Veri Madenciliği alanındaki temel görevlerden biridir. Kullanıldığı uygulama alanlarının listesi geniştir: görüntü segmentasyonu, pazarlama, sahtekarlıkla mücadele, tahmin, metin analizi ve diğerleri. Açık modern sahne Kümeleme genellikle veri analizinin ilk adımıdır. Benzer gruplar belirlendikten sonra başka yöntemlere başvurulur ve her grup için ayrı bir model oluşturulur.
Kümeleme problemi şu veya bu şekilde istatistik, örüntü tanıma, optimizasyon ve makine öğrenimi gibi bilimsel alanlarda formüle edilmiştir. Dolayısıyla küme kavramı için eşanlamlıların çeşitliliği - sınıf, takson, yoğunlaşma.
Şu anda, nesne gruplarını kümelere bölmeye yönelik yöntemlerin sayısı oldukça fazladır - birkaç düzine algoritma ve hatta bunların daha fazlası. Ancak biz algoritmaların Veri Madenciliğindeki uygulamaları açısından kümelenmesiyle ilgileniyoruz.
Veri Madenciliğinde Kümeleme
Veri Madenciliğinde Kümeleme, veri analizinin ve eksiksiz bir analitik çözüm oluşturmanın aşamalarından biri olarak hareket ettiğinde değerli hale gelir. Bir analistin benzer nesne gruplarını tanımlaması, özelliklerini incelemesi ve her grup için oluşturması genellikle daha kolaydır. ayrı model tüm veriler üzerinde genel bir model oluşturmaktan daha iyidir. Bu teknik, pazarlamada, müşteri gruplarının, alıcıların, ürünlerin tanımlanmasında ve her biri için ayrı bir strateji geliştirilmesinde sürekli olarak kullanılır.
Çoğu zaman Veri Madenciliği teknolojisinin karşılaştığı veriler aşağıdaki önemli özelliklere sahiptir:
- yüksek boyutlu (binlerce alan) ve büyük hacimli (yüzbinlerce ve milyonlarca kayıt) veritabanı tabloları ve veri ambarları (ultra büyük veritabanları);
- veri kümeleri büyük sayılar içeriyor sayısal Ve kategorikÖznitellikler.
Nesnelerin tüm nitelikleri veya özellikleri aşağıdakilere ayrılmıştır: sayısal(sayısal) ve kategorik(kategorik). Sayısal nitelikler uzayda sıralanabilen niteliklerken, kategorik nitelikler sıralanamayan niteliklerdir. Örneğin, "yaş" özelliği sayısaldır, "renk" ise kategoriktir. Değerlerin niteliklere atfedilmesi, seçilen ölçek türüyle yapılan ölçümler sırasında meydana gelir ve bu genel olarak konuşursak ayrı bir görevdir.
Çoğu kümeleme algoritması, nesnelerin bir miktar yakınlık (benzerlik) ölçüsüne dayalı olarak birbirleriyle karşılaştırılmasını içerir. Yakınlık ölçüsü, bir sınırı olan ve nesnelerin yakınlığı arttıkça artan bir niceliktir. Benzerlik ölçümleri özel kurallara göre "icat edilir" ve spesifik ölçümlerin seçimi ölçüm ölçeğinin yanı sıra göreve de bağlıdır. Sayısal nitelikler için yakınlık ölçüsü olarak sıklıkla kullanılır. Öklid mesafesi, aşağıdaki formülle hesaplanır:
$$D (x, y)=\sqrt(\sum_(i)((x-y)^2))$$
Veri Madenciliğinde büyük miktarlarda veriyi işleme ihtiyacı, mümkünse kümeleme algoritmasının karşılaması gereken gereksinimlerin formüle edilmesine yol açmıştır. Şimdi onlara bakalım:
- Veritabanından mümkün olan minimum geçiş sayısı;
- Sınırlı çalışma rasgele erişim belleği bilgisayar;
- Daha sonra hesaplamalara devam etmek için algoritma durdurulabilir ve ara sonuçlar kaydedilebilir;
- Algoritma, veritabanındaki nesneler yalnızca tek yönlü imleç modunda (yani kayıt gezinme modunda) alınabildiğinde çalışmalıdır.
Bu gereksinimleri (özellikle ikincisini) karşılayan bir algoritma çağrılacaktır. ölçeklenebilir(ölçeklenebilir). Ölçeklenebilirlik, hesaplama karmaşıklığına ve yazılım uygulamasına bağlı olarak bir algoritmanın en önemli özelliğidir. Daha kapsamlı bir tanım da var. Sabit bir RAM kapasitesiyle, veritabanındaki kayıt sayısındaki artışla çalışma süresi doğrusal olarak artıyorsa, bir algoritmaya ölçeklenebilir denir.
Ancak çok büyük miktarda veriyi işlemek her zaman gerekli değildir. Bu nedenle, küme analizi teorisinin oluşumunun şafağında, algoritmaların ölçeklenebilirliğine neredeyse hiç dikkat edilmedi. İşlenen tüm verilerin RAM'e sığacağı varsayıldı; asıl vurgu her zaman kümelemenin kalitesinin iyileştirilmesiydi. Yüksek kaliteli kümeleme ile ölçeklenebilirlik arasında bir denge kurmak zordur. Bu nedenle ideal olarak Veri Madenciliği cephaneliği her ikisini de içermelidir. verimli algoritmalar mikrodizilerin kümelenmesi ve büyük veritabanlarının işlenmesi için ölçeklenebilir olması.
Kümeleme algoritmaları: parlaklık ve sefalet
Dolayısıyla küme algoritmalarını şu şekilde sınıflandırmak zaten mümkündür: ölçeklenebilir Ve ölçeklenemez. Sınıflandırmaya devam edelim.
Kümelere bölme yöntemine dayanan algoritmalar iki türdür: hiyerarşik ve hiyerarşik olmayan. Klasik hiyerarşik algoritmalar oluştururken yalnızca kategorik niteliklerle çalışır tam ağaç iç içe geçmiş kümeler. Küme hiyerarşileri oluşturmaya yönelik toplayıcı yöntemler burada yaygındır; bunlar, başlangıç nesnelerinin sıralı bir şekilde birleştirilmesini ve küme sayısında buna karşılık gelen bir azalmayı içerir. Hiyerarşik algoritmalar göreceli olarak sağlar yüksek kalite kümelemedir ve küme sayısının önceden ayarlanmasını gerektirmez. Çoğu O(n 2) karmaşıklığına sahiptir.
Hiyerarşik olmayan algoritmalar, bir dizi nesnenin belirli bir anlamda kümelere en uygun şekilde bölünmesini belirleyen belirli bir amaç fonksiyonunun optimizasyonuna dayanır. Bu grupta popüler olan, amaç fonksiyonu olarak nesne koordinatlarının istenen kümelerin merkezlerinden kare ağırlıklı sapmalarının toplamını kullanan k-ortalamalar ailesinin algoritmalarıdır (k-ortalamalar, bulanık c-ortalamalar, Gustafson-Kessel). . Kümelerde küresel veya elipsoidal şekiller aranır. Kanonik uygulamada, fonksiyon Lagrange çarpan yöntemine göre minimize edilir ve yalnızca en yakın yerel minimumun bulunmasına izin verir. Küresel arama yöntemlerinin (genetik algoritmalar) kullanılması, algoritmanın hesaplama karmaşıklığını önemli ölçüde artıracaktır.
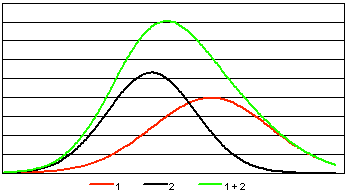
Mesafeye dayalı olmayan hiyerarşik olmayan algoritmalar arasında EM algoritması (Beklenti-Maksimizasyon) öne çıkarılmalıdır. Küme merkezleri yerine, her küme için karşılık gelen matematiksel beklenti değeri ve varyansa sahip bir olasılık yoğunluk fonksiyonunun varlığını varsayar. Bir dağılım karışımında (Şekil 2), bunların parametreleri (ortalamalar ve standart sapmalar) maksimum olabilirlik ilkesi kullanılarak aranır. EM algoritması böyle bir aramanın uygulamalarından biridir. Sorun, algoritmaya başlamadan önce, genel veri seti içerisinde tahmin edilmesi zor olan dağılım türleri hakkında bir hipotezin ortaya konulmasıdır.
Bir nesnenin nitelikleri karıştırıldığında başka bir sorun ortaya çıkar; bir kısım sayısal tipte, diğer kısım ise kategorik tiptedir. Örneğin aşağıdaki nesneler arasındaki mesafeyi niteliklerle (Yaş, Cinsiyet, Eğitim) hesaplamanız gerektiğini varsayalım:
(1) (23, koca, daha yüksek)
(2) (25, kadın, ortalama).
İlk özellik sayısaldır, geri kalanı kategoriktir. Herhangi bir benzerlik ölçüsüyle klasik bir hiyerarşik algoritma kullanmak istiyorsak, bir şekilde Age niteliğini gözden düşürmemiz gerekecek. Örneğin şöyle:
(1) (30 yaş altı, koca, yüksek öğrenim)
(2) (30 yaşına kadar, kadın, ortaöğretim).
Bu durumda kesinlikle bazı bilgileri kaybedeceğiz. Uzaklığı Öklid uzayında tanımlarsak, kategorik niteliklerle ilgili sorular ortaya çıkacaktır. “Kocanın cinsiyeti” ile “Kadının cinsiyeti” arasındaki mesafenin 0'a eşit olduğu açıktır çünkü bu özelliğin değerleri adlandırma ölçeğindedir. “Eğitim” özelliği ise hem isim ölçeğinde hem de sıra ölçeğinde her değere belirli puanlar verilerek ölçülebilir. Hangi seçeneği seçmeliyim? Peki ya kategorik nitelikler sayısal olanlardan daha önemliyse? Bu sorunların çözümü analistin omuzlarına düşüyor. Ayrıca k-means algoritması ve benzerleri kullanıldığında, kategorik niteliklerin küme merkezlerinin anlaşılmasında ve küme sayısının önceden belirlenmesinde zorluklar ortaya çıkar.
Hiyerarşik olmayan mesafeye dayalı algoritmalarda amaç fonksiyonunu optimize etmeye yönelik algoritma doğası gereği yinelemelidir ve her yinelemede nesneler arasındaki mesafelerin bir matrisini hesaplamak gerekir. Şu tarihte: çok sayıda Bu, verimsizdir ve ciddi bilgi işlem kaynakları gerektirir. K-ortalamalar algoritmasının 1. yinelemesinin hesaplama karmaşıklığı O(kmn) olarak tahmin edilir; burada k,m,n sırasıyla kümelerin, niteliklerin ve nesnelerin sayısıdır. Ancak çok fazla yineleme olabilir! Veri seti üzerinden birçok geçiş yapmanız gerekecektir.
Küresel veya elipsoidal şekilli kümeleri arama fikrine sahip yaklaşımın kendisi, k-ortalamalarda birçok dezavantaja sahiptir. Yaklaşım, uzaydaki veriler birbirinden açıkça ayırt edilebilen kompakt kümeler oluşturduğunda işe yarar. Ve eğer veriler iç içe yerleştirilmişse, o zaman k-means algoritmalarının hiçbiri böyle bir görevin üstesinden gelemez. Ayrıca, bir kümenin diğerlerinden çok daha büyük olması ve birbirine yakın olması durumunda algoritma iyi çalışmaz - büyük bir kümenin "bölünmesi" etkisi ortaya çıkar (Şekil 3).

Ancak kümeleme algoritmalarının iyileştirilmesi alanında araştırmalar devam etmektedir. K-ortalamalar algoritmasının ilginç uzantıları, kategorik nitelikler (k-modlar) ve karma niteliklerle (k-prototipler) çalışmak üzere geliştirilmiştir. Örneğin k-prototypes, öznitelik türüne bağlı olarak nesneler arasındaki mesafeleri farklı şekilde hesaplar.
Ölçeklenebilir kümeleme algoritmaları pazarında, mücadele, algoritma çalışırken veri kümesinden geçen her "ekstra" geçişi azaltmaktır. K-ortalamalar ve EM'nin ölçeklenebilir analogları (ölçeklenebilir k-ortalamalar ve ölçeklenebilir EM), ölçeklenebilir toplayıcı yöntemler (CURE, CACTUS) geliştirilmiştir. Bu son teknoloji ürünü algoritmalar, son kümelemeyi elde etmeden önce yalnızca birkaç (iki ila on) veritabanı taraması gerektirir.
Ölçeklenebilir algoritmaların elde edilmesi, vazgeçme fikrine dayanmaktadır. yerel optimizasyon fonksiyonları. K-means algoritmasında nesnelerin birbirleriyle ikili olarak karşılaştırılması yerel optimizasyondan başka bir şey değildir, çünkü Her yinelemede kümenin merkezinden her nesneye olan mesafenin hesaplanması gerekir. Bu durum yüksek hesaplama maliyetlerine yol açmaktadır. Ayar yaparken küresel optimizasyon fonksiyonları, kümeye yeni bir nokta eklemek büyük hesaplamalar gerektirmez: eski değere, yeni nesneye ve sözde küme özellikleri(küme özellikleri). Belirli küme özellikleri belirli bir algoritmaya bağlıdır. BIRCH, LargeItem, CLOPE ve diğer birçok algoritma bu şekilde ortaya çıktı.
Dolayısıyla tek bir evrensel kümeleme algoritması yoktur. Herhangi bir algoritmayı kullanırken avantajlarını ve dezavantajlarını anlamak, en iyi şekilde çalıştığı verilerin doğasını ve ölçeklendirme yeteneğini dikkate almak önemlidir.
Edebiyat
- Bradley, P., Fayyad, U., Reina, C. Kümeleme Algoritmalarını Büyük Veritabanlarına Ölçeklendirme, Proc. 4. Uluslararası Konf. Bilgi Keşfi ve Veri Madenciliği, AAAI Press, Menlo Park, Kaliforniya, 1998.
- Zhang, T., Ramakrishnan, R., Livny, M. Birch: Büyük Veritabanları için Verimli Bir Veri Kümeleme Yöntemi, Proc. ACM SIGMOD Uluslararası Konf. Veri Yönetimi, ACM Press, New York, 1996.
- Paul S. Bradley, Usama M. Fayyad, Cory A. Reina Büyük Veritabanlarına EM (Beklenti-Maksimizasyon) Kümelemesini Ölçeklendirme, Microsoft Research, 1999.
- Z. Huang. Büyük veri kümelerinin karışık sayısal ve kategorik değerlerle kümelenmesi. Bilgi Keşfi ve Veri Madenciliği Birinci Pasifik-Asya Konferansında, 1997.
- Milenova, B., Campos, M. Ortogonal projeksiyonlar kullanarak büyük veritabanlarını sayısal ve nominal değerlerle kümeleme, Oracle Data Mining Technologies, 2002.
- Z. Huang. Veri Madenciliğinde çok büyük kategorik veri kümelerini kümelemek için hızlı bir kümeleme algoritması. Veri Madenciliği ve KDD ile İlgili Araştırma Sorunları, 1997.
- Wang, K., Xu, C.. Liu, B. Büyük öğeleri kullanarak işlemleri kümeleme. Proc'ta. CIKM'99, Kansas, Missouri, 1999.
- Guha S., Rastogi R., Shim K. CURE: Büyük Veritabanları için Verimli Bir Kümeleme Algoritması, Proc. ACM SIGMOD Uluslararası Konf. Veri Yönetimi, ACM Press, New York, 1998.
- Ganti V., Gerhke J., Ramakrishan R. CACTUS – Özetleri Kullanarak Kategorik Verileri Kümeleme. Proc KDD'99, 1999'da.
- J. Bilmes. EM Algoritması ve Gauss Karışımı ve Gizli Markov Modelleri için Parametre Tahminine Uygulanması Üzerine Nazik Bir Eğitim, Tech. Rapor ICSI-TR-97-021, 1997.
- Ultra büyük veritabanlarında veri madenciliği / V. Ganti, J. Gerke, R. Ramakrishnan // Açık sistemler, №9-10, 1999.
- Barseghyan ve ark. Veri analizi yöntemleri ve modelleri: OLAP ve Veri Madenciliği. – St.Petersburg, 2004.
Dünyanın Güneş etrafında dönen 8 gezegenden biri olduğunu biliyoruz. Güneş, Samanyolu galaksisindeki yaklaşık 200 milyar yıldız arasında yalnızca bir yıldızdır. Bu rakamı anlamak oldukça zordur. Bunu bilerek evrendeki yıldızların sayısı hakkında yaklaşık 4X10^22 varsayımında bulunabiliriz. Gökyüzünde yaklaşık bir milyon yıldız görebiliyoruz, ancak bu gerçek yıldız sayısının yalnızca küçük bir kısmı. Yani iki sorumuz var:
- Galaksi nedir?
- Peki galaksiler ile yazının konusu arasındaki bağlantı nedir (küme analizi)
Galaksi yıldızlar, gaz, toz, gezegenler ve yıldızlararası bulutlardan oluşan bir koleksiyondur. Tipik olarak galaksiler spiral veya edeptik bir şekle benzer. Uzayda galaksiler birbirinden ayrılmıştır. Büyük kara delikler genellikle çoğu galaksinin merkezleridir.
Bir sonraki bölümde tartışacağımız gibi galaksiler ile küme analizi arasında pek çok benzerlik vardır. Galaksiler üç boyutlu uzayda bulunur, küme analizi çok değişkenli analiz n boyutlu uzayda gerçekleştirilir.
Not: Kara delik bir galaksinin merkezidir. Küme analizi için merkezlerle ilgili benzer bir fikir kullanacağız.
Küme analizi
Diyelim ki bir telekomünikasyon şirketinde pazarlama ve tüketici ilişkileri sorumlususunuz. Her tüketicinin farklı olduğunu ve farklı tüketicileri çekmek için farklı stratejilere ihtiyacınız olduğunu anlıyorsunuz. Maliyetleri optimize etmek için müşteri segmentasyonu gibi bir aracın gücünü takdir edeceksiniz. Küme analizi bilginizi tazelemek için, 8 tüketiciyi ve onların çağrılarının ortalama süresini (yerel ve uluslararası) gösteren aşağıdaki örneği inceleyin. Aşağıdaki veriler:
Daha iyi anlaşılması için x ekseninin uluslararası aramaların ortalama süresini, y ekseninin ise yerel aramaların ortalama süresini gösterdiği bir grafik çizelim. Grafik aşağıdadır:

Not: Bu, gece gökyüzündeki yıldızların dizilişini analiz etmeye benzer (burada yıldızların yerini tüketiciler alır). Ayrıca üç boyutlu bir uzay yerine, x ve y eksenleri olarak yerel ve uluslararası çağrıların süresine göre tanımlanan iki boyutlu bir uzayımız var.
Şimdi, galaksiler açısından konuşursak, görev şu şekilde formüle edilmiştir: Kara deliklerin konumunu bulmak; kümeleme analizinde bunlara merkezler denir. Merkezleri tespit etmek için, merkez konumları olarak rastgele noktaları alarak başlayacağız.
Kümeler için Centroidleri bulmak için Öklid mesafesi
Bizim durumumuzda, (1, 1) ve (3, 4) koordinatlarına sahip noktalara keyfi olarak iki ağırlık merkezi (C1 ve C2) yerleştireceğiz. Neden bu iki merkezi seçtik? Grafikteki noktaların görsel gösterimi bize analiz edeceğimiz iki kümenin olduğunu gösteriyor. Ancak ilerleyen zamanlarda bu sorunun cevabının büyük bir veri seti için bu kadar basit olmadığını göreceğiz.Daha sonra, iki nokta arasındaki mesafeyi bulmak için Öklid formülünü kullanarak ağırlık merkezleri (C1 ve C2) ile grafikteki tüm noktalar arasındaki mesafeyi ölçeceğiz.
Not: Mesafe başka formüller kullanılarak hesaplanabilir; örneğin,
- kare Öklid mesafesi - birbirinden daha uzaktaki nesnelere ağırlık vermek için
- Manhattan mesafesi – emisyonların etkisini azaltmak için
- Güç mesafesi – belirli koordinatlar boyunca etkiyi artırmak/azaltmak için
- anlaşmazlık yüzdesi – kategorik veriler için
- ve benzeri.
Centroid üyeliği (son sütun), centroidlere (C1 ve C2) yakınlığa göre hesaplanır. İlk tüketici, ağırlık merkezi #1'e daha yakındır (2,24'e kıyasla 1,41) ve bu nedenle, ağırlık merkezi C1 olan kümeye aittir.

Aşağıda C1 ve C2 merkez noktalarını (mavi ve turuncu bir elmas olarak gösterilmiştir) gösteren bir grafik bulunmaktadır. Tüketiciler, atandıkları kümenin ilgili merkezinin rengiyle tasvir edilir.

Merkezleri rastgele seçtiğimiz için ikinci adım bu seçimi yinelemeli hale getirmektir. Yeni pozisyon Centroidler karşılık gelen kümenin noktalarının ortalaması olarak seçilir. Örneğin, ilk ağırlık merkezi için (bunlar 1, 2 ve 3 numaralı tüketicilerdir). Bu nedenle, C1 ağırlık merkezi için yeni x koordinatı bu tüketicilerin ortalama x koordinatıdır (2+1+1)/3 = 1,33. C1 (1.33, 2.33) ve C2 (4.4, 4.2) için yeni koordinatlar alacağız. Yeni grafik aşağıdadır:

Son olarak, ağırlık merkezlerini karşılık gelen kümenin merkezine yerleştireceğiz. Aşağıdaki grafik:

Örneğimizdeki kara deliklerimizin (küme merkezleri) konumları C1 (1,75, 2,25) ve C2'dir (4,75, 4,75). Yukarıdaki iki küme, uzayda birbirinden ayrılmış iki galaksi gibidir.
Öyleyse örneklere daha detaylı bakalım. Tüketicileri iki parametreye göre segmentlere ayırma göreviyle karşı karşıya kalalım: yaş ve gelir. Diyelim ki sırasıyla 90.000 $ ve 62.000 $ gelire sahip, yaşları 37 ve 44 olan 2 tüketicimiz var. (37, 90000) ve (44, 62000) noktaları arasındaki Öklid mesafesini ölçmek istersek şunu görürüz: bu durumda Gelir değişkeni yaş değişkenine “hakimdir” ve bu değişkenin değişimi mesafe üzerinde güçlü bir etkiye sahiptir. Bu sorunu çözmek için bazı stratejilere ihtiyacımız var, aksi takdirde analizimiz yanlış sonuç verecektir. Bu sorunun çözümü değerlerimizi karşılaştırılabilir ölçeklere getirmektir. Sorunumuzun çözümü normalleşmedir.
Veri Normalleştirme
Veri normalleştirmeye yönelik birçok yaklaşım vardır. Örneğin minimum-maksimum normalizasyon. Bu normalleştirme için aşağıdaki formül kullanılırbu durumda X* normalleştirilmiş değerdir; minimum ve maksimum, tüm X kümesindeki minimum ve maksimum koordinatlardır.
(Bu formülün tüm koordinatları segmente yerleştirdiğini unutmayın)
Örneğimizi düşünün, maksimum gelir 130.000 ABD Doları ve minimum tutar 45.000 ABD Dolarıdır. A tüketicisi için normalleştirilmiş gelir değeri
![]()
Bu alıştırmayı her değişkenin (koordinatların) tüm noktaları için yapacağız. İkinci tüketicinin (62000) geliri ise normalleşme süreci sonrasında 0,2 olacak. Ayrıca minimum ve maksimum yaş sırasıyla 23 ve 58 olsun. Normalleşme sonrasında iki tüketicimizin yaşları 0,4 ve 0,6 olacak.
Artık tüm verilerimizin 0 ile 1 değerleri arasına düştüğünü görmek çok kolay. Dolayısıyla artık karşılaştırılabilir ölçeklerde normalleştirilmiş veri setlerine sahibiz.
Unutmayın, küme analizi işleminden önce normalizasyon işleminin yapılması gerekmektedir.
Giriş türleri
- Nesnelerin özellik açıklaması. Her nesne, adı verilen bir dizi karakteristik özelliğiyle tanımlanır. işaretler. Özellikler sayısal veya sayısal olmayabilir.
- Nesneler arasındaki mesafelerin matrisi. Her nesne, eğitim setindeki diğer tüm nesnelere olan mesafelerle tanımlanır.
Kümelenmenin Hedefleri
- Küme yapısını tanımlayarak verileri anlama. Örneği benzer nesnelerden oluşan gruplara bölmek, basitleştirmenize olanak tanır ilave işlemler veri ve karar verme, her kümeye farklı bir analiz yöntemi uygulayarak (“böl ve yönet” stratejisi).
- Veri sıkıştırma. Orijinal örnek aşırı derecede büyükse, her kümeden en tipik bir temsilciyi bırakarak onu azaltabilirsiniz.
- Yeniliğin tespiti yenilik tespiti). Kümelerden herhangi birine eklenemeyen atipik nesneler tanımlanır.
İlk durumda küme sayısını küçültmeye çalışırlar. İkinci durumda, her küme içindeki nesnelerin yüksek düzeyde benzerliğini sağlamak daha önemlidir ve herhangi bir sayıda küme olabilir. Üçüncü durumda, en ilginç olanı, herhangi bir kümeye sığmayan bireysel nesnelerdir.
Tüm bu durumlarda, büyük kümeler daha küçük kümelere bölündüğünde ve onlar da daha küçük kümelere vb. bölündüğünde hiyerarşik kümeleme kullanılabilir. Bu tür sorunlara sınıflandırma sorunları denir.
Taksonomi ağaca benzer hiyerarşik bir yapıyla sonuçlanır. Bu durumda, her nesne ait olduğu tüm kümelerin genellikle büyükten küçüğe doğru listelenmesiyle karakterize edilir.
Benzerliğe dayalı taksonominin klasik örneği, 18. yüzyılın ortalarında Carl Linnaeus tarafından önerilen canlıların iki terimli isimlendirmesidir. Çok sayıda nesne hakkındaki bilgileri düzenlemek için birçok bilgi alanında benzer sistemleştirmeler inşa edilmiştir.
Kümeleme yöntemleri
Kümeleme probleminin resmi formülasyonu
Bir nesneler kümesi olsun ve kümelerin sayıları (isimler, etiketler) kümesi olsun. Nesneler arasındaki mesafe fonksiyonu belirtilir. Nesnelerin sınırlı bir eğitim örneği vardır. Örneği adı verilen ayrık alt kümelere bölmek gerekir. kümeler Böylece her küme metrik olarak benzer nesnelerden oluşur ve farklı kümelerin nesneleri önemli ölçüde farklıdır. Bu durumda her nesneye bir küme numarası atanır.
Kümeleme algoritması herhangi bir nesneye küme numarası atayan bir işlevdir. Bazı durumlarda küme önceden bilinir, ancak çoğu zaman görev, bir veya diğerinin bakış açısından en uygun küme sayısını belirlemektir. Kalite kriterleri kümelenme.
Edebiyat
- Ayvazyan S.A., Buchstaber V.M., Enyukov I.S., Meshalkin L.D. Uygulamalı istatistikler: sınıflandırma ve boyutluluğun azaltılması. - M .: Finans ve İstatistik, 1989.
- Zhuravlev Yu I., Ryazanov V.V., Senko O.V."Tanıma". Matematiksel yöntemler. Yazılım sistemi. Pratik uygulamalar. - M .: Phazis, 2006. ISBN 5-7036-0108-8.
- Zagoruiko N.G. Uygulamalı veri ve bilgi analizi yöntemleri. - Novosibirsk: IM SB RAS, 1999. ISBN 5-86134-060-9.
- Mandel kimliği. Küme analizi. - M .: Finans ve İstatistik, 1988. ISBN 5-279-00050-7.
- Shlesinger M., Hlavach V.İstatistik ve yapı tanıma üzerine on ders. - Kiev: Naukova Dumka, 2004. ISBN 966-00-0341-2.
- Hastie T., Tibshirani R., Friedman J.İstatistiksel Öğrenmenin Unsurları. - Springer, 2001. ISBN 0-387-95284-5.
- Jain, Murty, Flynn Veri kümeleme: bir inceleme. // ACM Hesaplama. Hayatta kalma. 31 (3) , 1999
Dış bağlantılar
Rusça
- www.MachineLearning.ru - makine öğrenimi ve veri madenciliğine adanmış profesyonel wiki kaynağı
- S. Nikolenko. Kümeleme algoritmaları üzerine ders slaytları
İngilizce
- COMPACT - Kümelenme Değerlendirmesi için Karşılaştırmalı Paket. Ücretsiz bir Matlab paketi, 2006.
- P. Berkhin, Kümeleme Veri Madenciliği Teknikleri Araştırması, Accrue Yazılımı, 2002.
- Jain, Murty ve Flynn: Veri Kümeleme: Bir İnceleme,ACM Komp. Hayatta Kalma, 1999.
- Hiyerarşik, k-ortalamalar ve bulanık c-ortalamaların başka bir sunumu için kümelemeye bu girişe bakın. Ayrıca Gaussianların karışımı hakkında da bir açıklama bulunmaktadır.
- David Dowe Karışım Modelleme sayfası- diğer kümeleme ve karışım modeli bağlantıları.
- kümeleme üzerine bir eğitim
- Çevrimiçi ders kitabı: Bilgi Teorisi, Çıkarım ve Öğrenme Algoritmaları, David J.C. MacKay, k-ortalama kümelemesi, yumuşak k-ortalama kümelemesi ve E-M algoritması ve E-M algoritmasının varyasyonel görünümü dahil olmak üzere türetmeler hakkında bölümler içerir.
- "Kendi Kendini Organize Eden Gen", rekabetçi öğrenme ve kendi kendini organize eden haritalar yoluyla kümelenmeyi açıklayan öğretici.
- kernlab - Çekirdek tabanlı makine öğrenimi için R paketi (spektral kümeleme uygulamasını içerir)
- Öğretici - Kümeleme Algoritmalarının tanıtımını içeren eğitim (k-ortalamalar, bulanık-c-ortalamalar, hiyerarşik, gaussianların karışımı) + bazı etkileşimli demolar (java uygulamaları)
- Veri Madenciliği Yazılımı - Veri madenciliği yazılımı sıklıkla kümeleme tekniklerini kullanır.
- Java Rekabetçi Öğrenme Uygulaması Kümeleme için Denetimsiz Sinir Ağlarından oluşan bir paket. Java'da yazılmıştır. Tüm kaynak koduyla tamamlayın.
Giriş türleri
- Nesnelerin özellik açıklaması. Her nesne, adı verilen bir dizi karakteristik özelliğiyle tanımlanır. işaretler. Özellikler sayısal veya sayısal olmayabilir.
- Nesneler arasındaki mesafelerin matrisi. Her nesne, eğitim setindeki diğer tüm nesnelere olan mesafelerle tanımlanır.
Mesafe Matrisiözellik açıklamaları arasına mesafe fonksiyonunun (metrik) nasıl dahil edileceğine bağlı olarak, nesnelerin özellik açıklamalarından oluşan bir matristen sonsuz sayıda yolla hesaplanabilir. Öklid metriği sıklıkla kullanılır, ancak çoğu durumda bu seçim buluşsaldır ve yalnızca kolaylık nedenlerinden kaynaklanmaktadır.
Ters problemin (nesneler arasındaki ikili mesafelerden oluşan bir matristen özellik açıklamalarını geri yükleme) genel durumda bir çözümü yoktur ve yaklaşık çözüm benzersiz değildir ve önemli bir hataya sahip olabilir. Bu sorun çok boyutlu ölçeklendirme yöntemleriyle çözülmektedir.
Böylece kümeleme probleminin formülasyonu mesafe matrisi daha geneldir. Öte yandan, eğer özellik açıklamaları mevcutsa, daha etkili kümeleme yöntemleri oluşturmak çoğu zaman mümkündür.
Kümelenmenin Hedefleri
- Küme yapısını tanımlayarak verileri anlama. Örneği benzer nesnelerden oluşan gruplara bölmek, her kümeye farklı bir analiz yöntemi ("böl ve yönet" stratejisi) uygulayarak daha fazla veri işlemeyi ve karar vermeyi basitleştirmeyi mümkün kılar.
- Veri sıkıştırma. Orijinal örnek aşırı derecede büyükse, her kümeden en tipik bir temsilciyi bırakarak onu azaltabilirsiniz.
- Yenilik tespiti. Kümelerden herhangi birine eklenemeyen atipik nesneler tanımlanır.
İlk durumda küme sayısını küçültmeye çalışırlar. İkinci durumda, her küme içindeki nesnelerin yüksek (veya sabit) derecede benzerliğini sağlamak daha önemlidir ve herhangi bir sayıda küme olabilir. Üçüncü durumda, en ilginç olanı, herhangi bir kümeye sığmayan bireysel nesnelerdir.
Tüm bu durumlarda, büyük kümeler daha küçük kümelere bölündüğünde ve onlar da daha küçük kümelere vb. bölündüğünde hiyerarşik kümeleme kullanılabilir. Bu tür sorunlara sınıflandırma sorunları denir.
Taksonomi ağaca benzer hiyerarşik bir yapıyla sonuçlanır. Bu durumda, her nesne ait olduğu tüm kümelerin genellikle büyükten küçüğe doğru listelenmesiyle karakterize edilir. Taksonomi görsel olarak dendrogram adı verilen bir grafik biçiminde temsil edilir.
Benzerliğe dayalı taksonominin klasik bir örneği canlıların binom isimlendirilmesi 18. yüzyılın ortalarında Carl Linnaeus tarafından önerildi. Çok sayıda nesne hakkındaki bilgileri düzenlemek için birçok bilgi alanında benzer sistemleştirmeler inşa edilmiştir.
Mesafe fonksiyonları
Kümeleme yöntemleri
- İstatistiksel kümeleme algoritmaları
- Hiyerarşik kümeleme veya sınıflandırma
Kümeleme probleminin resmi formülasyonu
Bir nesneler kümesi olsun ve kümelerin sayıları (isimler, etiketler) kümesi olsun. Nesneler arasındaki mesafe fonksiyonu belirtilir. Nesnelerin sınırlı bir eğitim örneği vardır. Örneği adı verilen ayrık alt kümelere bölmek gerekir. kümeler Böylece her küme metrik olarak benzer nesnelerden oluşur ve farklı kümelerin nesneleri önemli ölçüde farklıdır. Bu durumda her nesneye bir küme numarası atanır.
Kümeleme algoritması herhangi bir nesneye küme numarası atayan bir işlevdir. Bazı durumlarda küme önceden bilinir, ancak çoğu zaman görev, bir veya diğerinin bakış açısından en uygun küme sayısını belirlemektir. Kalite kriterleri kümelenme.
Kümeleme (denetimsiz öğrenme), orijinal nesnelerin etiketlerinin başlangıçta belirtilmemesi ve hatta kümenin kendisinin bile bilinmemesi açısından sınıflandırmadan (denetimli öğrenme) farklıdır.
Kümeleme sorununun çözümü temelde belirsizdir ve bunun birkaç nedeni vardır:
- Açıkça mevcut değil en iyi kriter kümelenme kalitesi. Bir dizi buluşsal kriterin yanı sıra, açıkça tanımlanmış bir kritere sahip olmayan, ancak "yapı gereği" oldukça makul kümeleme gerçekleştiren bir dizi algoritma bilinmektedir. Hepsi farklı sonuçlar verebilir.
- Kümelerin sayısı genellikle önceden bilinmez ve bazı subjektif kriterlere göre belirlenir.
- Kümelemenin sonucu, seçimi kural olarak öznel olan ve bir uzman tarafından belirlenen metriğe önemli ölçüde bağlıdır.
Bağlantılar
- Vorontsov K.V. Vakalardan Öğretim için Matematiksel Yöntemler. MIPT (2004), Moskova Devlet Üniversitesi Hesaplamalı Matematik ve Kültür (2007).
- Sergey Nikolenko. Ders slaytları “Kümeleme Algoritmaları 1” ve “Kümeleme Algoritmaları 2”. Kurs "Kendi kendine öğrenen sistemler".
Edebiyat
- Ayvazyan S.A., Buchstaber V.M., Enyukov I.S., Meshalkin L.D. Uygulamalı istatistikler: sınıflandırma ve boyutluluğun azaltılması. - M .: Finans ve İstatistik, 1989.
- Zhuravlev Yu I., Ryazanov V.V., Senko O.V."Tanıma". Matematiksel yöntemler. Yazılım sistemi. Pratik uygulamalar. - M.: Fasis, 2006. .
- Zagoruiko N.G. Uygulamalı veri ve bilgi analizi yöntemleri. - Novosibirsk: IM SB RAS, 1999. .
- Mandel kimliği. Küme analizi. - M.: Finans ve İstatistik, 1988. .
- Shlesinger M., Hlavach V.İstatistik ve yapı tanıma üzerine on ders. - Kiev: Naukova Dumka, 2004. .
- Hastie T., Tibshirani R., Friedman J.İstatistiksel Öğrenmenin Unsurları. -Springer, 2001.
Selamlar!
onun içinde diploma çalışması Bir inceleme yaptım ve Karşılaştırmalı analiz veri kümeleme algoritmaları. Halihazırda toplanmış ve işlenmiş materyalin birileri için ilginç ve faydalı olabileceğini düşündüm.
Yazıda kümelemenin ne olduğundan bahsetmiştim. İskender'in sözlerini kısmen tekrarlayıp kısmen ekleyeceğim. Ayrıca ilgilenenler bu makalenin sonundaki kaynakçadaki bağlantılardan materyalleri okuyabilirler.
Ayrıca kuru "mezun" sunum tarzını daha gazetecilik tarzına getirmeye çalıştım.
Kümeleme kavramı
Kümeleme (veya küme analizi), bir dizi nesneyi küme adı verilen gruplara bölme görevidir. Her grupta “benzer” nesneler bulunmalıdır ve nesneler farklı gruplar mümkün olduğunca farklı olmalıdır. Kümeleme ve sınıflandırma arasındaki temel fark, grup listesinin net bir şekilde tanımlanmaması ve algoritmanın çalışması sırasında belirlenmesidir.Kümeleme analizinin uygulanması Genel görünüm aşağıdaki adımlara gelir:
- Kümeleme için bir nesne örneğinin seçilmesi.
- Örnekteki nesnelerin değerlendirileceği bir dizi değişkenin tanımlanması. Gerekirse değişkenlerin değerlerini normalleştirin.
- Nesneler arasındaki benzerlik ölçü değerlerinin hesaplanması.
- Benzer nesnelerden oluşan gruplar (kümeler) oluşturmak için küme analizi yönteminin uygulanması.
- Analiz sonuçlarının sunumu.
Mesafe önlemleri
Peki nesnelerin “benzerliğini” nasıl tespit edeceğiz? Öncelikle, her nesne için bir özellik vektörü oluşturmanız gerekir - kural olarak bu, örneğin bir kişinin boyu ve ağırlığı gibi bir dizi sayısal değerdir. Ancak niteliksel (kategorik denilen) özelliklerle çalışan algoritmalar da vardır.Özellik vektörünü belirledikten sonra, tüm bileşenlerin “mesafe” hesaplamasına eşit şekilde katkıda bulunmasını sağlayacak şekilde normalizasyon gerçekleştirilebilir. Normalleştirme işlemi sırasında tüm değerler belirli bir aralığa getirilir, örneğin [-1, -1] veya .
Son olarak, her bir nesne çifti için aralarındaki “mesafe”, yani benzerlik derecesi ölçülür. Pek çok metrik var, işte sadece ana olanları:
Farklı ölçümler kullanıldığında kümeleme sonuçları önemli ölçüde farklılık gösterebileceğinden, ölçüm seçimi tamamen araştırmacıya aittir.
Algoritmaların sınıflandırılması
Kendim için kümeleme algoritmalarının iki ana sınıflandırmasını belirledim.- Hiyerarşik ve düz.
Hiyerarşik algoritmalar (taksonomi algoritmaları olarak da adlandırılır), numunenin yalnızca bir bölümünü ayrık kümeler halinde oluşturmakla kalmaz, aynı zamanda iç içe geçmiş bölümlerden oluşan bir sistem oluşturur. O. Sonuç olarak, kökü numunenin tamamı olan ve yaprakları en küçük kümeler olan bir kümeler ağacı elde ederiz.
Düz algoritmalar nesnelerin bir bölümünü kümeler halinde oluşturur. - Açık ve bulanık.
Açık (veya örtüşmeyen) algoritmalar her örnek nesneye bir küme numarası atar; her nesne yalnızca bir kümeye aittir. Bulanık (veya kesişen) algoritmalar, her nesneye, nesnenin kümelerle ilişkisinin derecesini gösteren bir dizi gerçek değer atar. Onlar. her nesne belirli bir olasılıkla her kümeye aittir.
Kümeleri birleştirme
Hiyerarşik algoritmaların kullanılması durumunda, kümelerin birbirleriyle nasıl birleştirileceği, aralarındaki "mesafelerin" nasıl hesaplanacağı sorusu ortaya çıkar. Birkaç metrik vardır:- Tek bağlantı (en yakın komşu mesafeleri)
Bu yöntemde iki küme arasındaki mesafe, farklı kümelerdeki en yakın iki nesne (en yakın komşular) arasındaki mesafeye göre belirlenir. Ortaya çıkan kümeler zincir oluşturma eğilimindedir. - Tam bağlantı (en uzak komşuların mesafesi)
Bu yöntemde, kümeler arasındaki mesafeler, farklı kümelerdeki (yani en uzak komşular) herhangi iki nesne arasındaki en büyük mesafeye göre belirlenir. Bu yöntem genellikle nesneler ayrı gruplardan geldiğinde çok işe yarar. Kümeler uzun bir şekle sahipse veya doğal tip“zincirlenmişse” bu yöntem uygun değildir. - Ağırlıksız ikili ortalama
Bu yöntemde iki farklı küme arasındaki mesafe, içindeki tüm nesne çiftleri arasındaki ortalama mesafe olarak hesaplanır. Yöntem, nesneler farklı gruplar oluşturduğunda etkilidir, ancak genişletilmiş ("zincir" tipi) kümeler durumunda da aynı derecede iyi çalışır. - Ağırlıklı ikili ortalama
Yöntem, karşılık gelen kümelerin boyutunun (yani içerdikleri nesnelerin sayısı) hesaplamalarda ağırlıklandırma faktörü olarak kullanılması dışında ağırlıklandırılmamış ikili ortalama yöntemiyle aynıdır. Bu nedenle eşit olmayan küme boyutlarının beklendiği durumlarda bu yöntem kullanılmalıdır. - Ağırlıksız ağırlık merkezi yöntemi
Bu yöntemde iki küme arasındaki mesafe, ağırlık merkezleri arasındaki mesafe olarak tanımlanır. - Ağırlıklı ağırlık merkezi yöntemi (medyan)
Bu yöntem, hesaplamanın küme boyutları arasındaki farkları hesaba katmak için ağırlıklar kullanması dışında öncekiyle aynıdır. Bu nedenle küme boyutlarında önemli farklılıklar varsa veya şüpheleniliyorsa bu yöntem bir önceki yönteme tercih edilir.
Algoritmalara genel bakış
Hiyerarşik kümeleme algoritmaları
Hiyerarşik kümeleme algoritmaları arasında iki ana tür vardır: aşağıdan yukarıya ve yukarıdan aşağıya algoritmalar. Yukarıdan aşağıya algoritmalar yukarıdan aşağıya prensibiyle çalışır: Başlangıçta tüm nesneler bir kümeye yerleştirilir, daha sonra bu küme giderek daha küçük kümelere bölünür. Daha yaygın olanı, her nesneyi ayrı bir kümeye yerleştirerek başlayan ve ardından örnekteki tüm nesneler tek bir kümede yer alıncaya kadar kümeleri giderek daha büyük kümeler halinde birleştiren aşağıdan yukarıya algoritmalardır. Bu şekilde iç içe geçmiş bölmelerden oluşan bir sistem oluşturulur. Bu tür algoritmaların sonuçları genellikle bir ağaç (dendrogram) şeklinde sunulur. Böyle bir ağacın klasik bir örneği hayvanların ve bitkilerin sınıflandırılmasıdır.Kümeler arasındaki mesafeleri hesaplamak için herkes çoğunlukla iki mesafe kullanır: tek bir bağlantı veya tam bir bağlantı (kümeler arasındaki mesafe ölçümlerine genel bakışa bakın).
Hiyerarşik algoritmaların bir dezavantajı, çözülen problem bağlamında gereksiz olabilecek tam bölümler sistemidir.
İkinci Dereceden Hata Algoritmaları
Kümeleme problemi, nesnelerin gruplara en uygun şekilde bölünmesinin oluşturulması olarak düşünülebilir. Bu durumda optimallik, bölümlemedeki ortalama karekök hatanın en aza indirilmesi gerekliliği olarak tanımlanabilir:
Nerede cj- kümenin “kütle merkezi” J(belirli bir küme için ortalama özelliklere sahip nokta).
İkinci dereceden hata algoritmaları bir tür düz algoritmadır. Bu kategorideki en yaygın algoritma k-means yöntemidir. Bu algoritma oluşturur verilen numara kümeler birbirlerinden mümkün olduğu kadar uzağa yerleştirilir. Algoritmanın çalışması birkaç aşamaya ayrılmıştır:
- Rastgele seç k kümelerin başlangıçtaki "kütle merkezleri" olan noktalar.
- Her nesneyi en yakın “kütle merkezine” sahip kümeye atayın.
- Kümelerin "kütle merkezlerini" mevcut bileşimlerine göre yeniden hesaplayın.
- Algoritmayı durdurma kriteri karşılanmazsa 2. adıma dönün.
Bu algoritmanın dezavantajları, bölümleme için küme sayısını belirtme ihtiyacını içerir.
Bulanık Algoritmalar
En popüler bulanık kümeleme algoritması c-means algoritmasıdır. K-means yönteminin bir modifikasyonudur. Algoritma adımları:
Küme sayısının önceden bilinmediği veya her nesnenin açık bir şekilde bir kümeye atanmasının gerekli olduğu durumlarda bu algoritma uygun olmayabilir.
Grafik teorisine dayalı algoritmalar
Bu tür algoritmaların özü, seçilen nesnelerin bir grafik olarak temsil edilmesidir. G=(V, E) köşeleri nesnelere karşılık gelen ve kenarları nesneler arasındaki "mesafeye" eşit bir ağırlığa sahip olan. Grafik kümeleme algoritmalarının avantajları açıklık, göreceli uygulama kolaylığı ve geometrik hususlara dayalı olarak çeşitli iyileştirmeler sunma yeteneğidir. Ana algoritmalar, bağlı bileşenleri tanımlamaya yönelik algoritma, minimum yayılan ağaç oluşturmaya yönelik algoritma ve katman katman kümeleme algoritmasıdır.Bağlı bileşenleri tanımlamak için algoritma
Bağlı bileşenleri tanımlamaya yönelik algoritmada giriş parametresi belirtilir R ve grafikte "mesafelerin" daha büyük olduğu tüm kenarlar silinir R. Yalnızca en yakın nesne çiftleri bağlı kalır. Algoritmanın amacı böyle bir değeri seçmektir R, grafiğin birkaç bağlantılı bileşene "ayrıldığı" tüm "mesafeler" aralığında yer alır. Ortaya çıkan bileşenler kümelerdir.Bir parametre seçmek için R Genellikle ikili mesafelerin dağılımlarının bir histogramı oluşturulur. İyi tanımlanmış bir veri küme yapısına sahip görevlerde, histogramın iki tepe noktası olacaktır; biri küme içi mesafelere, ikincisi ise kümeler arası mesafelere karşılık gelir. Parametre R bu tepeler arasındaki minimum bölgeden seçilir. Aynı zamanda uzaklık eşiğini kullanarak küme sayısını kontrol etmek oldukça zordur.
Minimum yayılan ağaç algoritması
Minimum yayılan ağaç algoritması, öncelikle bir grafik üzerinde minimum yayılan ağaç oluşturur ve ardından en büyük ağırlığa sahip kenarları sırayla kaldırır. Şekil dokuz nesne için elde edilen minimum kapsayan ağacı göstermektedir.
6 birim uzunluğunda CD etiketli bir bağlantıyı çıkararak (kenarlı) maksimum mesafe), iki küme elde ederiz: (A, B, C) ve (D, E, F, G, H, I). İkinci küme daha sonra 4,5 birim uzunluğa sahip olan EF kenarı kaldırılarak iki kümeye daha bölünebilir.
Katman katman kümeleme
Katman-katman kümeleme algoritması, nesneler (köşeler) arasındaki belirli bir mesafe seviyesindeki bağlı grafik bileşenlerinin tanımlanmasına dayanmaktadır. Mesafe seviyesi mesafe eşiğine göre ayarlanır C. Örneğin nesneler arasındaki mesafeKatman katman kümeleme algoritması, grafiğin bir dizi alt grafiğini oluşturur G kümeler arasındaki hiyerarşik ilişkileri yansıtan:
![]() ,
,
Nerede G t = (V, E t)- seviye grafiği t ile,![]() ,
,
t ile– t-inci mesafe eşiği,
m – hiyerarşi seviyelerinin sayısı,
G 0 = (V, o), o, şu şekilde elde edilen boş grafik kenarları kümesidir: t 0 = 1,
G m = G yani mesafe (grafik kenarlarının uzunluğu) sınırlaması olmayan nesnelerin grafiğidir, çünkü t m = 1.
Mesafe eşiklerini değiştirerek ( s 0 , …, s m), burada 0 = 0'dan itibaren < 1'den < …< m ile= 1 ise, ortaya çıkan kümelerin hiyerarşisinin derinliğini kontrol etmek mümkündür. Böylece katman katman kümeleme algoritması, verilerin hem düz hem de hiyerarşik bir bölümünü oluşturma yeteneğine sahiptir.
Algoritmaların karşılaştırılması
Algoritmaların hesaplama karmaşıklığıAlgoritma karşılaştırma tablosu
| Kümeleme algoritması | Küme şekli | Giriş verileri | sonuçlar |
| Hiyerarşik | özgür | Hiyerarşiyi kısaltmak için küme sayısı veya mesafe eşiği | İkili küme ağacı |
| k-anlamına gelir | Hiperküre | Küme sayısı | Küme merkezleri |
| c-anlamına gelir | Hiperküre | Küme sayısı, bulanıklık derecesi | Küme merkezleri, üyelik matrisi |
| Bağlı bileşenlerin seçilmesi | özgür | Mesafe eşiği R | |
| Az yer kaplayan ağaç | özgür | Kenarların kaldırılması için küme sayısı veya mesafe eşiği | Kümelerin ağaç yapısı |
| Katman katman kümeleme | özgür | Mesafe eşikleri dizisi | Kümelerin ağaç yapısı farklı seviyelerde hiyerarşi |
Uygulama hakkında biraz
Çalışmamda hiyerarşik yapılardan (ağaçlardan) bireysel alanlar seçmem gerekiyordu. Onlar. esasen orijinal ağacı birkaç parçaya daha kesmek gerekiyordu küçük ağaçlar. Yönlendirilmiş ağaç, grafiğin özel bir durumu olduğundan, grafik teorisini temel alan algoritmalar doğal bir uyum sağlar.Tamamen bağlantılı bir grafiğin aksine, yönlendirilmiş bir ağaçta tüm köşeler kenarlarla bağlanmaz ve toplam kenar sayısı n-1'dir; burada n, köşelerin sayısıdır. Onlar. Ağaç düğümleriyle ilgili olarak, herhangi bir sayıda kenarın kaldırılması ağacı bağlı bileşenlere (bireysel ağaçlar) "parçalayacağından" bağlı bileşenleri tanımlamaya yönelik algoritmanın çalışması basitleştirilecektir. Bu durumda minimum yayılan ağaç algoritması, bağlı bileşenlerin seçilmesine yönelik algoritmayla örtüşecektir - en uzun kenarların kaldırılmasıyla orijinal ağaç birkaç ağaca bölünür. Bu durumda minimum kapsayan ağacın oluşturulması aşamasının atlandığı açıktır.
Başka algoritmalar kullanılmış olsaydı, nesneler arasındaki bağlantıların varlığını ayrı ayrı hesaba katmaları gerekirdi, bu da algoritmayı karmaşıklaştırır.
Ayrı olarak şunu söylemek isterim ki, en iyi sonuç mesafe ölçülerinin seçimini denemek ve hatta bazen algoritmayı değiştirmek gerekir. Tek bir çözüm yok.